Checking for broken links on any website is part of many marketing strategies. Broken links can be used as a link-building strategy by people looking to replace those links on other people’s property with their own links, but you might be looking for broken links on your client’s website so that you can improve their user experience as well. Obviously, pointing your visitors towards a dead resource is a bad experience so that’s something you want to keep an eye on to offer your audience the most relevant resources at all time.
While there is already a plethora of tools that do such a job for free on the most famous platforms, I found that it would be a nice challenge to develop my own broken links finder application from scratch using Python. And so I thought that it would also make a great article to walk you through how I did it and to give you access to my application at the end as well.
If you’re only interested in running the application on your computer, feel free to scroll down to this part of the post for the setup guide. But obviously, it’s always nice to understand how a program works before running it on your own machine so I invite you to follow along the entirety of this guide :).
Also, if you’re interested in learning about more Technical SEO projects with Python that I completed, here is an article about multiple project ideas for you to play with: Python for SEO/Marketing: 5 Project Ideas for Beginners and Advanced Developers .
So without further ado, let’s get into the requirements for this tutorial and the guide itself!
Requirements
One thing I am quite happy about is that this application I developed does not take many external modules to function.
The only module that come from an external library that you might not have installed already is this wonderful Sitemap Parser developed by mediacloud.org . You can find the project page here. In order to install this module, simply “pip install ultimate-sitemap-parser” and we can get going.
The rest of the modules that we are going to use are the CSV library, BeautifulSoup, pandas, requests and Streamlit if you wish to turn it into a web application.
Roadmap
First things first, I want to give you a rundown of the steps we are going to take to make this project work.
- First, we are going to extract the list of all webpages from a website by parsing the sitemap with Python
- Second, we are going to scrape each individual page to get a list of every external link on the website with their location as well as their associated text value
- Thirdly, we are going to create a separate list with the unique external links
- Then, we are going to make a request for each external link to determine if they are valid links or if they’re offline or 404. The offending links will be placed into a separate list.
- Then, we will match the offending link back to where they are located within the website and under which text value they can be found.
- Finally, we will turn this result into a dataframe containing three columns:
- The URL Location where the offending external link is located
- The offending external link
- The text value where the link can be found within the webpage
Now that we effectively mapped out the steps, let’s solve each of these individually.
Extract List of a Website’s Pages with Python
As mentioned on the roadmap, the first step is to retrieve a list of all the pages present on a website.
To do so, we are using the Ultimate Sitemap Parser library.
These are the two functions I created for this purpose:
The first function makes use of the library previously mentioned in order to retrieve a list of all of the webpages available on a domain. The function requires one argument in order to work: The full domain you’re interested in, including HTTP protocol.
Because the sitemap parser will return multiple times the same URLs, the second function has been created to output a clean list that only contains one link for each of the webpages present on the website.
Now that we have our list of URLs, we can jump onto the second step of the roadmap.
How to find External Links on Webpages
The second step in our roadmap is to go through each of the URLs present in the list we created previously and to scrape the content of each page so we can find and extract the external links present in the target website as well as store their location and the text associated with them.
The first function is scraping each page of the website looking for external links and create a list of lists containing three elements: The URL where the external link was found, its destination and the anchor text of this external link.
Eventually, the second function is going through this list of external links and compiles a list of “unique” external links so that we will only have to identify if a link is broken or not once instead of going through all external links where many might be repeated.
These two functions are providing us with two things:
- A list of all of the external links, their location, destination and anchor text
- And a list of unique external links
Now that we have those two assets, we can proceed on the next step of the roadmap.
Identify Broken Links on a Website with Python
Now that we have our list of unique external links, we are going to have to ping them individually and collect their status code in order to identify if they’re valid or broken links. In order to do that, the requests library is perfect for this job as it’s able to ping websites and give us a status code like 200, or 404 that will help us determine whether or not a link is valid.
What the requests library also allow us to do is to let us know if a website is offline. A webpage whose website does not exist anymore is not considered a 404 but a Connection Error. Eventually, we will put these two in the same basket but it’s important to know that there is a difference.
Here is what I came up with to do this job:
The input for this function is the list of unique external links we got from the last function.
The output of this function is a list of broken links.
And we are almost done with this project! All that’s left to do is to figure where the broken links are located on the website so that we can easily spot them and put this in a dataframe for visualisation. So let’s get to this.
Match Broken Links to Content on the Website and Output Dataframe
This step was not too bad. Here is the function I came up with:
This function is harder to explain.
This function needs two things to work:
- The list of broken links created in the previous step
- The list of all of the external links as well as their location and anchor text that we created in the second step of the roadmap
From there, we’re able to go through all of the links and create a new list that only contains the URL of the broken link, the location of the broken link as well as its anchor text.
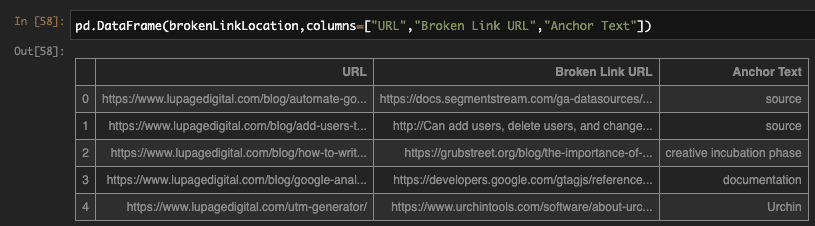
The output of this function is a dataframe with three columns, namely “URL”, “Broken Link URL” and “Anchor Text”.
And that’s it! Now you can make these functions work one after the other to get to this result. Here is me trying the tool on my friend’s website. Don’t hesitate to check his blog out if you’re looking for another technical marketer to follow.
Now. This is all fun but what if I told you there was a way we could turn these functions into an actual web application with an actual interface? If that sounds interesting, keep reading!
The Application
If you’re not familiar with Streamlit, Streamlit is a Python library that allows you to create web applications out of your python scripts. It differs from Django or Flask in the way that it’s extremely easy to get something running that is also good-looking.
I’ve been using it more and more often the past few months as it’s a perfect way to give your peers access to your scripts even if they have zero knowledge of Python.
Here is how my application looks like:
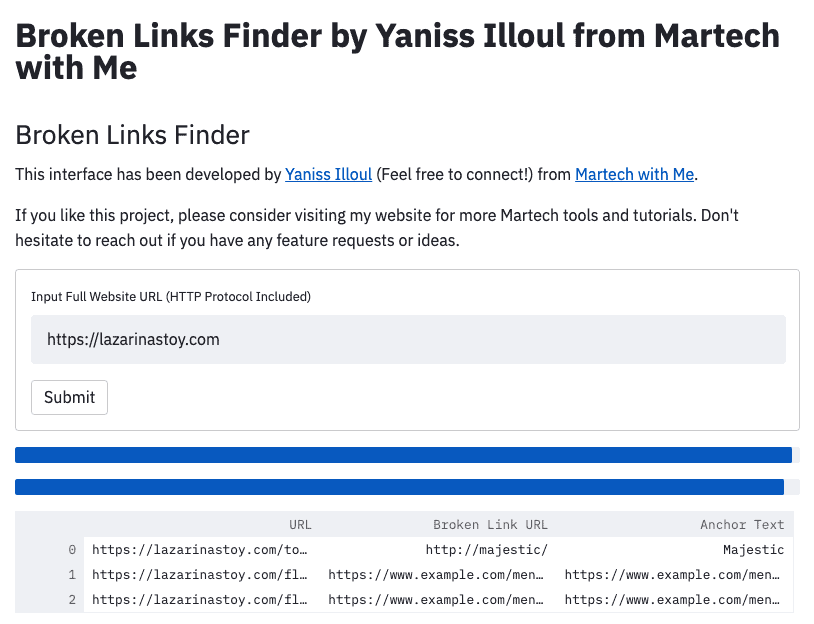
As you can see, it’s quite good looking and it takes zero front-end design knowledge to get to this point. it’s quite remarkable really.
Anyway, this broken link finder application will be available online in the next 4-5 days after publication of this article so keep your eyes peeled for this! If you can’t wait to use this tool as a web application, please reach out to me by email so I can sort you out!
Conclusion
And that’s it! I hope you learned something or you found what you were looking for. If you liked what you read, please do me a favour and consider joining my Marketing Technology newsletter! It’s a weekly newsletter that features new tools and insights from this industry and it’s followed by hundreds of technical marketers so I’m sure you would love it there!
Also please consider sharing this article on LinkedIn or on Slack if you think your peers could find this interesting, that would be really cool 🙂
Thank you for your time and I will catch you in the next article!



89 Responses
Is this available already? For example in a jupyter notebook?
3h4dqk
yovvue
f0e9gl
4sm46k
s6lh0p
9n2ijy
amf1t5
ymyo74
rik0vl
5gvyue
n0lbm7
lu93wv
21hoqq
v73hsb
ec0ff8
nr72gl
lybcde
turnix
qpflbh
7j1g9n
3wluag
uze8fh
nm572g
ln01b4
bqqpr6
35c5o9
qqngho
rvx2q3
shctpt
m5t6y9
s5slom
f0zpy7
dvvqhc
bo0f6z
zmf8my
4rd219
lfpnt9
2yfj4a
16y984
65sh09
8d24xq
kea9tp
ya1f6b
54tonb
erlv6d
rp4tz9
hx8rtn
jhcrdw
z6winm
4jajac
r1wh65
ko4edr
ldiy2c
35dk4w
ap8kt2
x6gb60
v6dwf7
oo7qlg
esuwvs
gefajm
bu271y
tdjp4q
oqi7nd
d323sj
cyl9hi