After having scoured the internet for a few specific tools, I found out that a lot of them offered really basic features for what I consider an awful lot of money. Eventually, I also found out that a lot of people were looking to learn Python in order to give themselves the ability to analyze their websites, their competitors’ or do other tasks with the intent of making some SEO data analysis.
In this article, I want to show you how I use Python to extract a list of all of the links of one website pointing to external domains. This is extremely practical to have an overview of how many external links per post a website is generating, have an idea of which domains someone is promoting a lot and can then be used for other purposes like checking for broken links or other stuff.
Anyway, without further ado, let’s get into it.
Requirements
To follow along this tutorial, there are a few things you will need to know and have installed on your machine.
I am using Python 3. If you are using Python 2, you should know how to translate my examples into the proper syntax.
You should know about the basics of Python. Creating and handling lists and functions should not be an issue. Working with classes is a plus but we are not going to create any in this tutorial.
In terms of library, we will need BeautifulSoup installed. It’s a pretty basic one but if you’ve never used it before, just make sure to install it (pip install bs4).
And that’s it, we are ready to jump in.
The way we are going to approach this whole project is as follow:
- Find the sitemap of a domain in order to list all of its indexed pages
- Go through each of its indexed pages and extract the external links
- Create a .CSV file with all of this information
Find the sitemap of a website.
So let’s start with the sitemap. This one does not require Python. Just head over to the domain you’re interested in mapping and add /sitemap.xml at the end of the URL. If you can not find a domain’s sitemap, you can use this handy free tool. By typing the domain you are interested in the main search field and waiting a bit, this tool should find you the exact URL of the sitemap of someone’s domain.
Now that we have our sitemap link, it is time to load up our Python notebook and write some code. We want to initialize our environment and charge it with all of the necessary stuff.
Get the list of Published Pages on a Website with Python
Because we are going to use BeautifulSoup and the whole project involves a lot of scraping, I am going to use my starter file for web-scraping in Python that I shared in this article.
As I already went over all of this code in the mentioned article, we will skip over which line does what but you should have all of this already lined up in your Python file:
Now is the time to load our sitemap into our Python file and parse its content with BeautifulSoup with the code shown below:
To give more context to the users not accustomed to BeautifulSoup, the goal with this library is to go through the source code of a page and extract the information we are interested in. The lines 3, 4 and 5 are the basic lines necessary in order to have access to a page’s source code. It’s the equivalent of right-clicking in a page and selecting “View Page Source”, but with Python.
In the case of this tutorial, I am interested in scraping Gunxblast.fr, which is a video games website I own and that has a bit over 100 published articles which is a nice amount of data that we are going to have to extract and analyze.
A good way of web-scraping is to always have a browser version of the URL you’re trying to scrape opened in your browser. In my case, this is how the sitemap URL looks like on my screen:
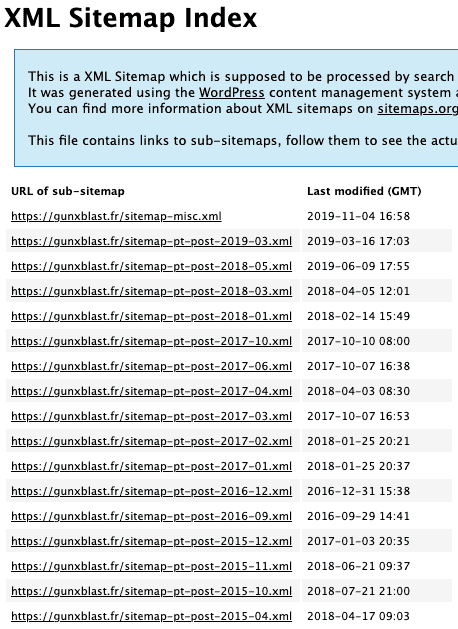
When I click on a link like the second one, I can see that this then gives me access to the actual URL of a published post.

That gives us an idea of how we are going to proceed. In order to reach these URLs, we are going to have to “open” each of these sitemap-pt-post XML links so that we can retrieve all of the articles’ URLs.
When we print our “soup” variable in Python, we can see that these XML links are between <loc> HTML tags.

In order to get within this loc tag, this is the code we are going to use:
Line 1 uses the “find_all” class of BeautifulSoup. It takes the argument of which HTML tag we are specifically interested in extracting, in our case the “loc” tag. The result is a list that contains all of a locs found in the sitemap provided earlier. As an example, printing list_of_locs[0] gives you this:

Line 2 is us creating an empty list where we are going to store all of the links afterwards.
Line 4 to 5 is a simple loop that goes through all of the loc tags found in Line 1 and extracts what is inside their tags. Doing loc.text allows us to only have what is between <loc> and </loc> in the screenshot above. This result is stored in the list we created in Line 2.
Line 7 is just there for us to see that we now have a list that contains all of the .XML links we needed.
Now, the goal is to inspect the source code of each one of these links. We are going to start by analyzing the first one.
We are basically doing the same thing as the beginning of this section but are using a different URL. By inspecting the “soup” variable here, we can see that the structure remains the same and that effectively, all of the URLs we are interested in are, once again, located between <loc> HTML tags.
Based on this finding, we can write a nice loop that will go through all of the links in our list_of_xml_links variable and extract once again the content of what is between the <loc> tags of each of these pages.
Line 1 is us creating an empty list where we are going to store all of the published pages’ URLs afterwards.
Line 3 to 7 is the beginning of a loop that goes through every XML link and retrieves the source code of each of them one by one.
Line 9 to 12. Once it retrieved the source code of one page, we are doing the same as we did originally by looking for the content of the <loc> HTML tags. This time though, we are storing the results of the pages in a new list that we created in Line 1.
Running this code might take a slight amount of time. BeautifulSoup is reasonably fast but Python is not known for being the quickest language around. But eventually, this code should be done processing.
And this is how we finally get a list of every published pages/articles on this website. Printing “list_of_urls” will show you a list of every URL of articles online on the website:
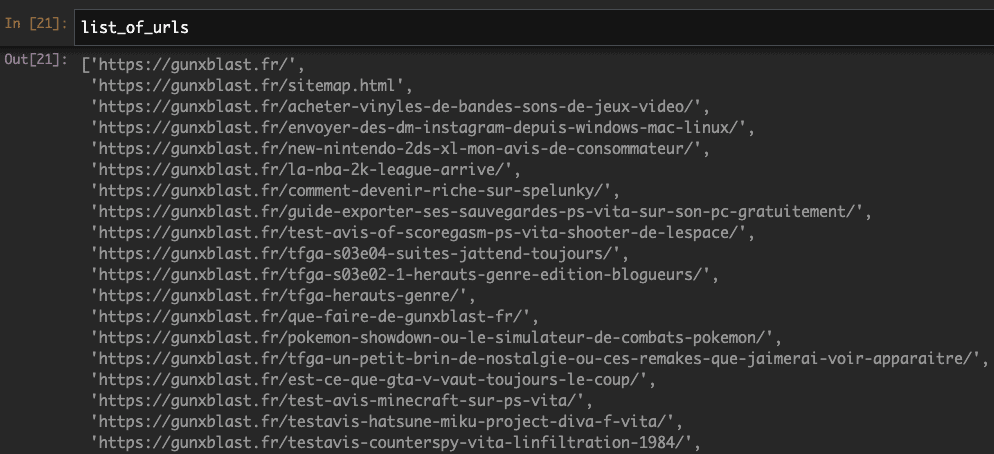
A quick len(list_of_urls) indicates that we have 123 URLs to analyze. Now, it is time to dig deeper into each one of these URLs and finally do what we came for here, which is finding these links pointing to external domains.
How to get a list of links in a webpage with Python
Now that we have our links, we can start playing with one article. In our case, I would like to focus on an article I wrote where I know I put a lot of external links. In the “list_of_urls” variable, this URL is number 2.
So as usual, we load this new URL into its own soup.
And now we run this new loop that will store all of the external domain URLs into a separate list.
Line 1 is us creating an empty list where we are going to store all of the external links afterwards.
Line 2 is the beginning of the loop through all of the links in the URL scraped in the set of code above this one.
Line 5 asks if the word “gunxblast.fr” is found within the href attribute of the links we are running in the loop or if the word “http” is not present. If there is indeed a “gunxblast.fr” or if there is a link without http in it, then we ask the script to skip it in Line 7 as we are not interested in internal links or javascript links here.
In Line 11, we store every link that does not meet the criterias mentioned above in the list we created in Line 1.
Eventually, this gives us a list of every external link present in this page:
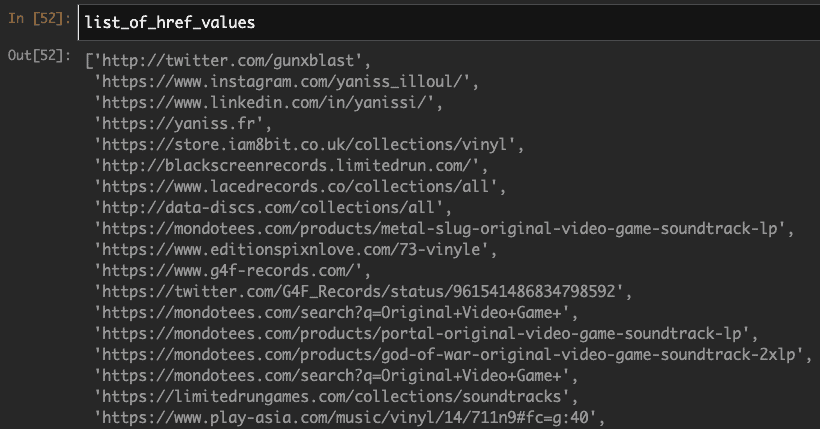
Everything is looking great so far. We developed a way of figuring every published page in a website and get a list of every external link within those pages. Now the only thing left to do is to develop a function that will loop through all of these URLs but also, we want to create a CSV featuring two columns: Column A should be the published URL page and Column B should be an external link URL. The goal, in this case, would be to end up with something that looks a bit like this:
| Page URL | External Link |
| https://gunxblast.fr/acheter-vinyles-de-bandes-sons-de-jeux-video/ | https://store.iam8bit.co.uk/collections/vinyl |
| https://gunxblast.fr/acheter-vinyles-de-bandes-sons-de-jeux-video/ | http://blackscreenrecords.limitedrun.com/ |
| https://gunxblast.fr/acheter-vinyles-de-bandes-sons-de-jeux-video/ | https://www.lacedrecords.co/collections/all |
| https://gunxblast.fr/acheter-vinyles-de-bandes-sons-de-jeux-video/ | http://data-discs.com/collections/all |
| https://gunxblast.fr/acheter-vinyles-de-bandes-sons-de-jeux-video/ | https://mondotees.com/products/metal-slug-original-video-game-soundtrack-lp |
So let’s build this up, shall we?
So, what is new?
I added a few comments and print notifications so that we can be able to monitor the progress of the script.
Line 67 and 77 are using a Try/Except method. If you are not familiar with the concept, it’s a very rudimental way of dealing with errors. In our case, I realized that a few URLs had very unconventional links that did not fit our scripts. By incorporating this Try/Except method, I am basically asking the script to not stop if it meets one error but to just ignore it and move on to the next link.
Line 49 is me creating a list that is going to be a list of lists. In the loop below, I am basically creating one list for every link that is like [url1,external_link1] then [url1, external_link2], etc. These lists with two items are then being added to a bigger list that will fill itself with lists of two items. Eventually, this mega list of lists of two items is what is going to be use to create the CSV.
Finally, Line 83 to 88 are brand new and are what is creating the CSV file. You can choose the name of your file in Line 85 and the title of your two columns in Line 87. Finally, Line 88 dumps all of the two items lists mentioned above into the CSV and saves the file.
And that’s it, you now have a CSV with every published page of the website you were interested in and every single external link within its pages.
Little PSA about the code. This is not optimised by any means. An advanced Python user could probably write this whole thing in less than 20 lines of code. The point of this exercise was to explain in depth every single step of the way. Don’t roast me in the comments if you know your Python :).
There’s also so many more things we can do. A small feature improvement one could achieve is also retrieving the “rel=” value in order to know which links are nofollow and which links are dofollow. Or to query every external link to find out which are broken links easily.
Now what? Well, I had a few ideas on how you can use this data in Google Sheets to draw some conclusions.
Ideas on what to do with the data
So, now that we have this file in our hands, it is time to do some reporting on what we can learn. Here is a list of things you can find out:
- How many external links do you have per article on average/median
- Which article has the most external links
- Which article has the least external links
- Which domain is the most pointed out to
- Any other ideas?
After importing my file in a Google Sheets, here is the kind of data I was able to get out of it:
Excluding my social media profiles and the links that are on every single page, on average, my video games blog has 3.8 external links per article. The median number of external links per article is 2. the article with the most external links has 33 of them while the one with the least links only has one.
The domain that is the most linked out to is Twitter as I used to mention other people’s tweets pretty often.
Conclusion
Anyway, that pretty much wraps up this analysis. I’m sure there are many other things one can do but as I said, this article has been written mostly as a guide for beginner Python marketers that want to start writing their first projects.
If you are interested in learning more about how to use Python as an element of your SEO strategy, make sure to let me know in the comments as I’m thinking this could be a series of articles to help other Python Marketers to develop their own stack of custom-made tools.
I would also really appreciate it if you would join my newsletter. this way you won’t miss any findings I’m sharing with you guys or articles that I publish that I think you may find interesting if you liked this one.
Best of luck with everything!



4 Responses
That’s a great script. But is there any method to check two or more websites at the same time?